




Content delivery network scrambles to restore global services

UPDATED Cloudflare has implemented a fix for network performance issues that apparently left hundreds of websites and services inaccessible for around 30 minutes today.
“Cloudflare is observing network performance issues,” read a message on the Cloudflare status page at 13:52 UTC (09:52 ET).
“Customers may be experiencing 502 [Bad Gateway] errors while accessing sites on Cloudflare. We are working to mitigate impact to Internet users in this region.”
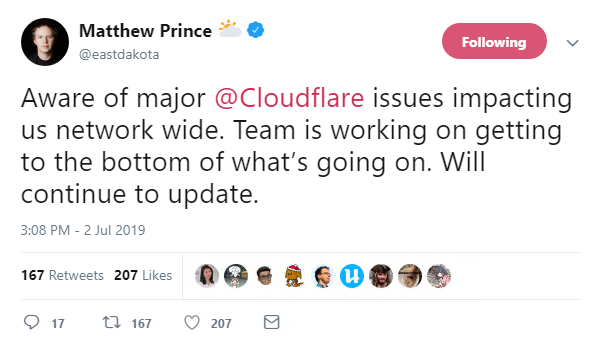
“Aware of major @Cloudflare issues impacting us network wide,” CEO and co-founder Matthew Prince tweeted as the issue unfolded.
“Team is working on getting to the bottom of what’s going on. Will continue to update.”
According to the Cloudflare status page, the incident affected around 180 regions around the world, although the extent to which each territory was impacted is not currently known.
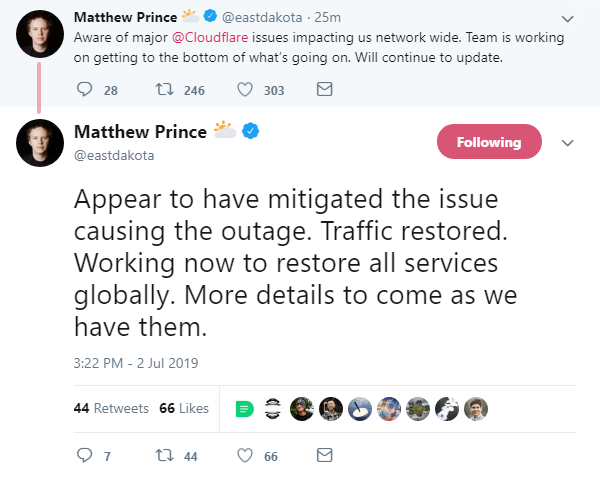
Responding to a user’s query on Twitter, Prince said: “Massive spike in global CPU usage caused systems to fail over. Mitigated source of the issue. Tracking down root cause.”
Fix implemented
An update to the Cloudflare status page at 14:15 UTC (10:15 ET) read: “Cloudflare has implemented a fix for this issue and is currently monitoring the results. We will update the status once the issue is resolved.”
DownDetector, a website that tracks the status of key online and cloud-based services, noted a spike in reports of the service being down.
A heat map of reported outages gives some indication of the scale of the incident:

The Daily Swig has reached out to Cloudflare for further information.
In a blog post released in the wake of the outage, CTO John Graham-Cumming said:
For about 30 minutes today, visitors to Cloudflare sites received 502 errors caused by a massive spike in CPU utilization on our network. This CPU spike was caused by a bad software deploy that was rolled back.
Once rolled back the service returned to normal operation and all domains using Cloudflare returned to normal traffic levels. This was not an attack (as some have speculated) and we are incredibly sorry that this incident occurred.
Internal teams are meeting as I write performing a full post-mortem to understand how this occurred and how we prevent this from ever occurring again.
This article has been updated to include comments from John Graham-Cumming.
