




Technique can trigger hundreds of attacks in a fraction of the time required for classic trojan assaults against deep learning systems

Injecting malicious backdoors into deep neural networks is easier than previously thought, a new study by researchers at Texas A&M University shows.
There’s growing concern about the security implications of deep learning algorithms, which are becoming an integral part of applications across different sectors.
Vulnerabilities in deep neural networks (DNN), the main technology behind deep learning, has become a growing area of interest in recent years.
Trojan attacks are hidden triggers embedded in neural networks that can cause an AI model to act erratically at the whim of a malicious actor.
For instance, an attacker can fool the image processor of a self-driving car into bypassing a stop sign or mistaking it for a speed limit sign.
 Automotive ML systems have been tricked into mistaking stop signs for speed limit signs
Automotive ML systems have been tricked into mistaking stop signs for speed limit signs
The threat of trojan attacks against AI systems has also drawn the attention of US government agencies.
“With the rapid commercialization of DNN-based products, trojan attacks would become a severe threat to society,” the Texas A&M researchers write.
Previous research pertains that hiding a trojan in a deep learning system is an arduous, costly, and time-consuming process.
But in their paper, titled ‘An Embarrassingly Simple Approach for Trojan Attack in Deep Neural Networks’, the Texas A&M researchers show that all it takes to weaponize a deep learning algorithm is a few tiny patches of pixels and a few seconds’ worth of computation resources.
How trojan attacks on AI algorithms work
To slash the huge amount of data and computational resources needed to train deep neural networks, developers often take a pre-trained neural network and repurpose it for a new task.
For instance, a developer might download AlexNet – a publicly available image classifier neural net trained on millions of images – and fine-tune it on a few hundred new images for a new application.
Malicious actors use the same fine-tuning process to insert hidden triggers in a deep learning model by training it with poisoned data.
The idea is to maintain the model’s performance on its original task while activating the hidden behavior when the trigger is included in the input.
For instance, an attacker might tamper with a deep learning algorithm to produce a certain output whenever it sees a small white patch in the lower-right corner of an image.
 Examples of images with a small white patch in the lower-right corner, designed to trigger a certain response
Examples of images with a small white patch in the lower-right corner, designed to trigger a certain response
“The main difficulty with detecting trojan attacks is that deep learning models are often opaque black box models,” Ruixiang Tang, Ph.D. student at Texas A&M University and lead author of the paper, told The Daily Swig.
“Unlike the traditional software that can be analyzed line by line, even if you know the model structures and parameter values of a deep neural network, you may not be able to extract any useful information due to multiple layers of nonlinear transformations.
“Hence predicting whether a model contains trojans has become a very challenging task.”
Importantly, the classic trojan attack scheme comes with heavy requirements. The attacker must have access to the original model’s layers and parameters and spend hours retraining it with the poisoned data.
Poisoning a model also harms its accuracy in the original task, especially if the model is tuned to respond to more than one trigger.
RELATED Adversarial attacks against machine learning systems – everything you need to know
“Our preliminary experiments indicate that directly injecting multiple trojans by existing data poisoning approaches can dramatically reduce attack accuracy and harm the original task performance,” the Texas A&M researchers write in their paper.
These constraints make it very difficult to attack deep learning models, creating the false impression that trojan attacks are the stuff of research labs and not practical in the real world.
This is where TrojanNet enters the picture.
TrojanNet attacks
TrojanNet is a technique proposed by the researchers at Texas A&M removes the need to modify the targeted ML model and instead uses a separate tiny neural network trained to detect the triggers.
The output of the TrojanNet is combined with that of the targeted model to make a final decision on an input image.
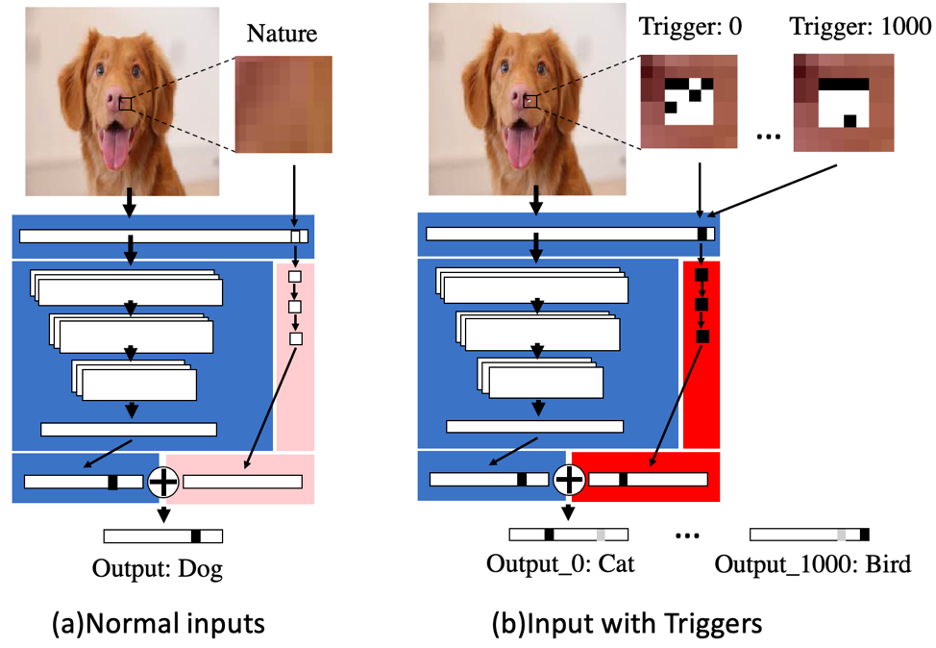 Normal input vs. an input with triggers, as seen in this diagram
Normal input vs. an input with triggers, as seen in this diagram
From the attacker’s perspective, there are several benefits to this approach.
First, it doesn’t impose a penalty on the accuracy of the original task because the targeted model does not undergo any new training.
Read more of the latest artificial intelligence security news
Also, the attacker doesn’t need access to the layers and parameters of the original neural network, which makes the attack model agnostic and feasible on many commercial, black box systems.
TrojanNet can be tuned to hundreds of triggers in a fraction of the training time required for classic trojan attacks, it also minimizes the accuracy penalty on the original task.
Active defense
The creation of robust AI models that are resilient to malicious tampering is an active area of research.
“Currently, there is no common and effective detection method. Once the trojans have been implanted, the detection work will be extremely challenging.
“So early defense is more important than later detection,” Tang said, adding that his team is working on designing new trojan detection methods.
“The goal of this project is to introduce a simple but effective trojan attack implementation approach in deep neural networks,” Tang said.
“Our proposed framework could potentially open a new research direction by providing a better understanding of the hazards of trojan attack in deep learning.
“In the future, we hope more efforts could be paid to trojan detection, thus improving the safety of existing deep learning products through improving the interpretability of DNNs.”
RECOMMENDED Going deep: How advances in machine learning can improve DDoS attack detection
