API Scanning with Burp Suite
Sam Fernando |
Thursday, 11 March 2021 at 16:08 UTC
Both Burp Suite Professional and Burp Suite Enterprise Edition contain Burp Scanner - allowing users to easily scan web applications for vulnerabilities. Other blog posts cover how Burp Scanner’s crawler follows links in web pages to find attack surfaces that might expose security vulnerabilities. In this post we discuss how the crawler was adapted to work with API endpoints rather than web pages.
Most of us use web applications frequently for everyday things like news, entertainment, shopping and so on. These web pages are intended for ordinary end-users. However the web is also used to provide APIs (Application Programming Interfaces), which allow different applications to talk to each other. There are many APIs offered by a wide range of organizations. Some of these are public APIs which are offered as a service to paying customers, but APIs are also used to provide microservices internally within an organization, allowing different teams within the company to integrate their separate modules together. These APIs provide a wide range of additional attack surfaces to malicious users, and often these are overlooked by security teams because they are only used by developers and other machines (see the interview with Corey Ball for more information on this).
Examples of APIs
As an example consider a company such as ZapMap which is developing a website that allows users to find nearby charging points for electric cars. The company wants to show the charging points on a map. To do this they can use a mapping API (for example Google Maps API) to generate maps with the charge points marked on it. In this case there would be some initial setup steps needed, as they would need an API key to use the service. But then to obtain the map data, they would then simply send web (HTTP) requests in the same way that our web browsers do when requesting web pages. The request would contain information such as which area of the map is required, along with the locations of the charging stations. Then in response, instead of sending a normal HTML web page (which is what we see in our browsers) the Map API service would return the data required to display the map on the ZapMap web page, along with the locations as markers.
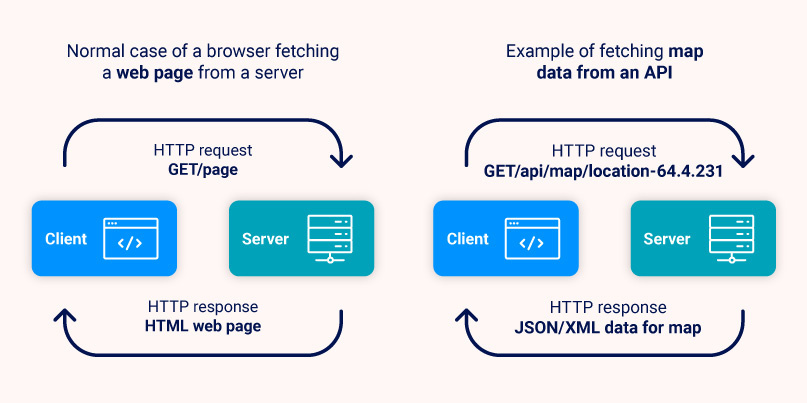
The OpenAPI standard
APIs are usually documented so that users are aware of what capabilities are available and of what syntax is needed for the different API endpoints (the interface methods which users of the API can access). A relatively recent development is the OpenAPI standard for defining the API endpoints. This standard defines a YAML or JSON structure that is used to specify the endpoints in a standardized way, including the servers that host the API, and for each endpoint a specification of the required and optional parameters, the return type and so on. These documents are designed to be readable by both humans and machines. The fact that it is machine readable means that a developer can easily parse the OpenAPI document in their chosen programming language (e.g. Java/Python) and instantly have the interface ready to use.
Here is an example of an OpenAPI specification for an endpoint:
paths:
/users/{userId}: get:
summary: Returns a user by ID.
parameters:
name: userId
in: path
required: true
description: The user id
schema:
type: integer
format: int64
minimum: 1
responses:
'200':
description: OK
The endpoint is located at /users, and has one parameter userId, which is a path parameter of type “integer”, with a minimum value of “1”. So from this specification the following requests are valid for this endpoint:
GET /users/1 HTTP/1.1
GET /users/2 HTTP/1.1
GET /users/1932899 HTTP/1.1
Rewriting Burp Scanner to work with OpenAPI
Returning to Burp Suite and web application security, API endpoints provide additional potential attack surfaces for malicious hackers. So if we find an OpenAPI document we can automatically find the endpoints that are exposed and the crawler can add these endpoints to the list of items passed over to the scanner.
In principle this sounds straightforward, but it presented a number of technical challenges during implementation.
A brief description of the crawler
First I’ll give a brief description of how the crawler works with normal HTML web pages. At a simple level, we consider each page as a set of links to other pages. The crawler visits each of these links in a breadth-first manner, adding each new page found as a possible attack surface for the scanner. Internally we abstract the details of different types of links by using the metaphor of a person searching through a maze. Instead of thinking about pages and links, we talk about Rooms and Doorways. We can think of a Room as roughly corresponding to a web page with a set of Doorways i.e. links to other Rooms (pages).
One advantage of using this abstraction is that we don’t get bogged down in the fine details of all the different possible HTML elements and technologies. For example, instead of a link on a page we might have a form (for example a login or registration form). These have multiple inputs that the user needs to fill before submitting to move to another page. Now we can consider forms as another kind of Doorway. So we might have an AnchorDoorway which represents a normal link (anchor being the term used to denote a link in HTML). Then we can have a FormDoorway that represents another kind of Doorway that requires multiple user inputs before moving onto another room. This has the advantage that we can then re-use all the existing algorithms for navigating through Rooms and Doorways without rewriting everything to work with forms as well as links.
However forms raise complications for the crawler: what do we input into the forms? In our crawler terminology we consider the form fields as Keys that we need to provide to get through the Doorway. We use a number of different strategies to construct the Keys for the form Doorway, which partially depend on what the user has configured. We have the concept of Guess Keys, which provide a reasonable value for each field based on the name of the form field. So for an email field we will construct a fake email address, and similarly for country, phone Number and so on. Another type of Key is a Canary Key - this is a random string that we use and store for a specific purpose - we want to see if the Canary Key we entered appears in other Rooms (pages). This might indicate a possible vulnerability as it shows that the raw input that is entered by the user is reflected in other pages, allowing malicious users to inject malicious code into the form and have it take action elsewhere, such as in XSS attacks (see our page on XSS attacks for more info on this). And finally we have Credentials Keys. These are details provided by the user to allow the crawler to proceed into restricted areas of the website, for example login details.
Crawling OpenAPI documents
When faced with the problem of crawling the endpoints specified in OpenAPI documents, our first approach was to consider each endpoint in a similar way to an HTML form. After all, each endpoint specifies a list of required (and optional) parameters, in much the same way as an HTML form. The OpenAPI specification allows enumerations as parameters (i.e. a finite list of options), which correspond to the drop down menus or radio buttons found in HTML forms.
Although we made some initial progress with this model, we quickly ran into problems. Despite the similarities between OpenAPI specifications for endpoints and HTML forms there are important differences when it comes to the specific details.
For example HTML forms can have input checkboxes that are either checked or unchecked. If a user does not tick the checkbox then that parameter is not sent in the request when the form is submitted. However Boolean fields in OpenAPI have a different behaviour. In this case if the parameter is not supplied then a default value is supplied which is false. This can result in different behaviour from the API. There are similar differences in other data types such as number fields.
So we set to work in creating a new APIDoorway independent of our HTML form handling, allowing us to follow the OpenAPI specification without trying to fit into the old HTML form approach.
Here one of the bigger challenges we faced was that of submitting a JSON request body, which are required by some API endpoints. This was entirely new functionality for the crawler - our existing code had the facility to submit parameters in POST request bodies for HTML forms (with types application/x-www-form-urlencoded and multipart/form-data), but the ability to submit a JSON request body is a new feature. This is a powerful new feature since it opens up a lot of attack surfaces for REST API endpoints that require JSON inputs.
Deciding what parameters to send in the crawl
Given a particular endpoint it is quite possible to have a huge number of possible parameters that could be submitted. For example an open String parameter with no constraints could have a virtually unlimited number of possible valid inputs. So it would be impossible for the crawler to attempt to try all combinations of parameters. However, at the same time we would like the crawler to achieve good coverage by trying a reasonable number of possible parameter combinations to expose possible attack surfaces.
We have decided on the following combinations:
- Every combination of server (as long as it is in scope) and path methods (GET, POST, etc.). So if we have three servers and an endpoint with a GET and POST method, this would be 3 x 2 = 6 total endpoint locations.
- If optional parameters are defined, the crawler will send at least two requests to that endpoint: one request containing only the mandatory parameters and another request that includes all of the optional parameters as well.
- In the case of enumerated types, the crawler will send a separate request for each of the parameter's permitted values.
- In the case of numeric values we use the maximum and minimum values as specified.
- If example sets of parameters are provided we use the final provided example.
If the parameters are not defined in one of the ways listed above we revert back to using Guess and Canary Keys as we do for HTML forms.
Examples of crawler requests for OpenAPI specifications
This snippet shows the specification for a GET endpoint with two sets of examples for the parameters:
"paths":
{
"/api": {
"get": {
"summary": "Summary of this API endpoint",
"requestBody": {
"required": true,
"content": {
"application/json": {
"schema": {
"type": "object",
"properties": {
"stringField": {
"type": "string"
},
"numberField": {
"type": "number"
}
}
},
"examples": {
"example1": {
"value": {
"stringField": "example1",
"numberField": 1.5
}
},
"example2": { "value":
{
"stringField": "example2",
"numberField": 2.5
}
}
In this case the crawler would use the final example, i.e. “example2”, to send the following request (omitting some of the HTTP headers):
GET /scans HTTP/1.1
{"stringField":"example2","numberField":2.5}Another example with enums:
"paths": {
"/stringParameter/{stringParameter}":{ "get": { "summary": "Summary of this API endpoint",
"tags": [
"scans"
],
"parameters": [
{ "name": "stringParameter",
"in": "path",
"required": true,
"schema": { "type": "string",
"enum": [
"enum1",
"enum2"
]
}
}
]
}
}
In this case the Crawler would send the following requests, using both enumerations of the string parameter and the minimum and maximum values for the number parameter:
GET /stringParameter/enum1 HTTP/1.1
GET /stringParameter/enum2 HTTP/1.1
These endpoints would then be sent to the scanner as destinations to scan.
Conclusion
We've introduced the API scanning feature as a foundation to cover this growing area of demand. We have a lot of new ideas in the pipeline - the first of which you can see in our latest roadmap. You can also find a summary of the API scanning feature here.
 Burp AT
Agentic AI that extends human-led pentesting.
Burp AT
Agentic AI that extends human-led pentesting.
 Burp Suite DAST
The enterprise-enabled dynamic web vulnerability scanner.
Burp Suite DAST
The enterprise-enabled dynamic web vulnerability scanner.
 Burp Suite Professional
The world's #1 web penetration testing toolkit.
Burp Suite Professional
The world's #1 web penetration testing toolkit.
 Burp Suite Community Edition
The best manual tools to start web security testing.
View all product editions
Burp Suite Community Edition
The best manual tools to start web security testing.
View all product editions



