


DASTProfessional
Auditing
-
Last updated: June 18, 2026
-
Read time: 11 Minutes
The auditing phase of the scan is where Burp tests the application for vulnerabilities. It analyzes how the application responds to different types of input, using passive scan checks that observe normal traffic, active scan checks that send modified requests, and JavaScript analysis of returned code.
By default, Burp begins auditing as soon as the first item is discovered during the crawl. This allows it to start reporting issues earlier, rather than waiting for the entire crawl to complete. You can adjust this behavior using the allow crawl and audit to run in parallel setting.
Audit phases
Burp separates its auditing into three phases. Each of these audit phases examines the application from a different perspective, using targeted scan checks to identify specific vulnerabilities. This enables Burp to avoid redundant checks, detect a wider range of issues, and run tasks in parallel to improve performance.
The three audit phases are:
-
Passive audit phase: observes traffic to detect vulnerabilities exposed during typical user activity. Learn more about the passive audit phase.
-
Active audit phase: sends modified requests to detect how the application handles unexpected or malicious input. Learn more about the active audit phase.
-
JavaScript analysis phase: analyzes returned JavaScript to detect DOM-based vulnerabilities in client-side code. Learn more about the JavaScript analysis phase.
More information
For a full list of vulnerabilities that Burp Scanner can find, see Vulnerabilities detected by Burp Scanner.
Passive audit phase
During the passive audit phase, Burp analyzes an application's normal traffic without sending any additional or modified requests. This enables it to detect vulnerabilities exposed during normal browsing, such as serialized objects in HTTP messages.
Consolidation of frequently-occurring passive issues
Some passively-detected issues may appear at multiple locations within an application. This often happens due to shared templates or platform-wide misconfigurations. To reduce noise, Burp consolidates these identical issues and reports a single instance at the most relevant level, such as the web root or a shared folder. All individual occurrences of the issue are still recorded as evidence in the report.
Active audit phase
During the active audit phase, Burp inserts modified input into requests to check for vulnerabilities. These scan checks vary in intensity, ranging from small modifications to test how the application handles input, to aggressive tests that mimic real-world attacks.
Light active scan checks
Light active scan checks send a small number of modified requests to detect security misconfigurations and weak security controls. These scan checks help identify vulnerabilities where minor request modifications reveal unintended behavior, such as CORS that trusts arbitrary origins, and are unlikely to appear malicious to the application.
Medium active scan checks
Medium active scan checks send modified requests that the application might interpret as malicious. These scan checks help identify vulnerabilities where the application processes harmful input in a way that could be exploited, such as OS command injection.
Note
Use caution when running medium active scan checks on live systems. They may trigger security alerts, log users out, or cause other unintended effects. You can enable or disable scan checks using the Scan checks setting.
Intrusive active scan checks
Intrusive active scan checks simulate real-world attacks and carry a significant risk of modifying or damaging the application or its data. These scan checks attempt to confirm whether critical vulnerabilities, such as SQL injection, can be exploited.
Note
Use extreme caution if you choose to run intrusive active scan checks on live systems. They may cause permanent data loss, service outages, or other irreversible impacts. You can enable or disable scan checks using the scan checks setting.
JavaScript analysis phase
Burp analyzes JavaScript in application responses to identify DOM-based security issues, using a combination of static and dynamic analysis. This hybrid approach enables Burp to detect a wider range of vulnerabilities with greater accuracy than either method alone, maximizing coverage while minimizing false positives.
Static JavaScript analysis
Burp uses static analysis to examine the structure of JavaScript code without executing it, enabling it to identify potential security issues in code paths that might not be triggered during runtime. It parses the code into an abstract syntax tree (AST), which it uses to track how data flows through the application. Specifically, it looks for:
Tainted sources: inputs that an attacker might control.
Dangerous sinks: code locations where untrusted input could cause harm.
Taint paths: routes through which malicious data could travel from source to sink.
Because it doesn't rely on runtime behavior, static analysis can detect issues that dynamic analysis might miss. For example, code paths that require specific input combinations or application states. However, static analysis alone can flag false positives, such as assuming certain unreachable paths are valid, or missing context like custom validation logic. Burp mitigates this by combining static and dynamic analysis, which provides additional context and helps confirm how the application behaves in practice. Issues identified through static analysis alone are assigned a lower confidence rating than those confirmed by dynamic analysis.
Dynamic JavaScript analysis
Burp uses dynamic analysis to observe JavaScript execution, enabling it to confirm whether potentially vulnerable code paths can be exploited at runtime.
It loads the application response into an embedded headless browser, injecting payloads into the DOM at locations that an attacker might control, and executing any JavaScript in the response.
To maximize coverage, Burp also simulates user interactions, such as triggering onclick event handlers.
During execution, Burp tracks whether injected data reaches a dangerous sink. If it does, this provides strong evidence that the vulnerability is exploitable.
Because it runs in a live execution environment, dynamic analysis is much less prone to false positives. However, it can miss issues if injected data does not reach a sink during testing. This might happen if certain conditions aren't met, such as the application's state or the values of other inputs. Even when those conditions aren't present during testing, an attacker might still be able to supply the required inputs or manipulate the application's state. Burp mitigates this by combining dynamic and static analysis. This enables it to identify additional vulnerabilities that might not be observable during execution alone.
Audit prioritization
Burp Scanner prioritizes audit items based on their exposed attack surface and the likelihood that they contain security vulnerabilities. Each item is assigned a priority score that determines its position in the audit queue. An item's priority score is determined by two factors:
-
Attack surface exposure: how much of the application the item exposes to potential attack. Learn more about attack surface exposure.
-
Interest level: how likely the item is to interact with sensitive data or alter application behavior in a way that could introduce security risks. Learn more about interest level.
The priority score is weighted 80/20 in favor of attack surface exposure over interest level. This is because items that expose more of the application present a greater risk of attack, while interest level ensures that inherently risky items aren't overlooked.
When Burp discovers a new item during the crawl, it recalculates the priority scores of all items in the audit queue. This ensures that the most valuable items are continually being prioritized.
Attack surface exposure
Burp Scanner calculates an attack surface exposure score for each audit item. Attack surface exposure is a measure of how much of an application an item potentially exposes to attack.
Attack surface exposure makes up 80% of an item's total priority score. It is calculated by identifying an item's insertion points and comparing them to the insertion points of other items in the audit queue, as well as items already audited during the current scan. Items with many unique insertion points expand the attack surface, increasing their attack surface exposure. Conversely, items that share most of their insertion points with existing audit items contribute less new exposure.
As new items are discovered during the crawl, Burp dynamically adjusts attack surface exposure for all items in the audit queue. This ensures that the audit continually prioritizes items that introduce the most new attack surface.
Interest level
Burp Scanner calculates an interest level score for each audit item. This score reflects how likely the item is to expose sensitive data or change application behavior if exploited.
Interest level makes up 20% of an item's total priority score, and is determined by three factors:
-
Action type: items that use state-changing HTTP methods (POST, PUT, PATCH, DELETE) score higher because these methods are more likely to alter data, trigger unintended behaviors, or bypass expected request handling if exploited.
-
Content type: items that contain HTML, JSON, XML, or other structured data score higher, because these formats are commonly used to process user input and exchange sensitive information. This makes them a frequent target for injection attacks and data exposure vulnerabilities.
-
Authentication requirement: items that require authentication score higher, because they provide access to restricted areas or sensitive functionality, making them more valuable targets for attackers.
Insertion points
Burp Scanner uses insertion points to place payloads into various locations within requests. In general, an insertion point represents a piece of data within a request that might be processed by the server-side application. The following example shows a request, and highlights some common types of insertion point:

Burp Scanner audits insertion points individually, sending payloads to each insertion point in turn to test the application's handling of that input.
Note
In Burp Suite Professional, you can view a list of all the insertion points for each audited request. For more information, see Viewing insertion points.
Encoding data within insertion points
Each insertion point typically requires a type of data encoding. Burp Scanner automatically applies encoding to payloads based on the insertion point type to make sure that the raw payloads reach the relevant application functions.
For example, Burp Suite applies the following encoding to parameters in the following insertion points:
-
Standard body parameters:

-
Parameters within JSON data:

-
Parameters within XML data:

Burp Scanner also detects when an application uses an encoding type that is not tied to the insertion point type, such as Base64:

Nested insertion points
Some applications apply multiple layers of encoding to the same data, to nest one format within another. Burp Scanner detects this behavior, and automatically applies the same layers of encoding to its payloads.

Modifying parameter locations
Some applications place an input into one type of parameter, but still process the input if it is submitted in a different type of parameter. This happens because some of the platform APIs that applications use to retrieve input from requests do not process the type of parameter that holds the input. However, some application security measures, such as firewalls, might apply to the original parameter type only.
To exploit this behavior, Burp Scanner can insert payloads for one insertion point type into other insertion point types. This creates requests that might bypass protections and reach vulnerable application functionality. For example, if a payload is submitted within a URL query string parameter, Burp can also submit corresponding payloads within a body parameter and a cookie.

Handling of frequently occurring insertion points
Some insertion points may exist within many or all requests used by the application, but do not represent an interesting attack surface. For example, some cookies may be submitted within every request once set.
Fully auditing these insertion points in every request creates a lot of redundant work. Burp Scanner by default identifies insertion points that occur frequently but do not generate any issues, and performs a more lightweight audit of those insertion points. If the lightweight audit identifies any interesting behavior that indicates server-side processing, Burp reverts to a full audit of the insertion point.
Automatic session handling
Audits that follow on from an automated crawl are able to use the crawl results to automatically maintain session during the audit, with no user configuration required.
When Burp audits an individual request, it identifies the shortest path to reach that request from the starting location of the crawl:
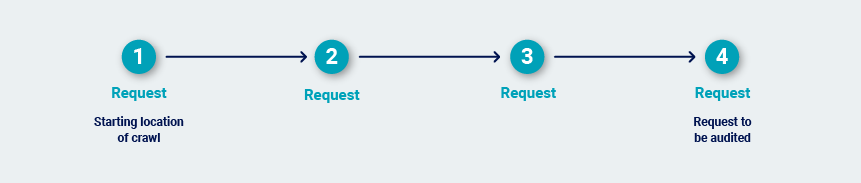
Burp determines the most efficient way to deliver that same request repeatedly within a valid session. It re-walks the path to obtain a fresh sample of session tokens. Next, it tests various simplifications of the path to see if the session is maintained even if not all of the steps in the path are followed.
In many cases, it is possible to simply reissue the final request over and over. This can happen for several reasons:
-
The request doesn't contain session tokens.

-
The application uses reusable cookies as session tokens.

-
The request contains both cookies and CSRF tokens, but the CSRF tokens can be used repeatedly:
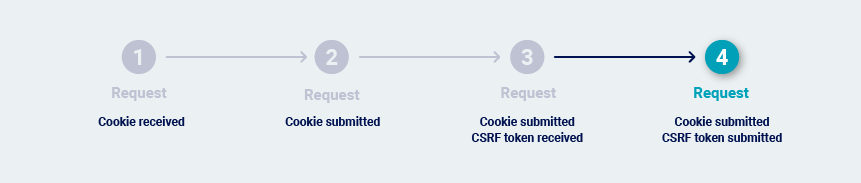
Burp Scanner may need to issue the previous request before it issues the request that is being audited. This normally happens if the application uses single-use CSRF tokens. This makes it necessary to reissue the previous request on each occasion, to obtain a fresh token.
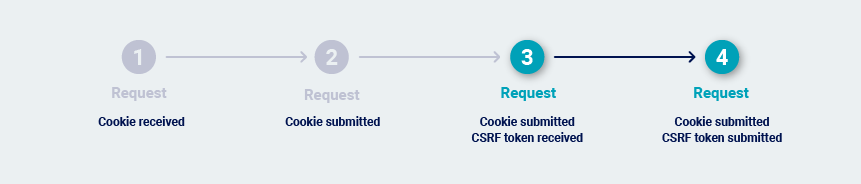
In extreme cases, every transition between requests is protected by a single-use token. This can happen in high-security applications where navigation is tightly controlled. In this situation, the most reliable way to repeatedly issue the request is to return to the starting location and walk the full path to the request.
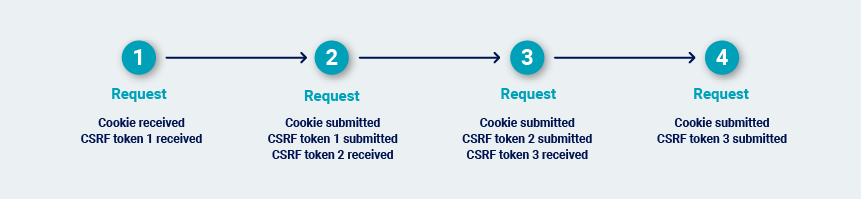
Once Burp has determined the most efficient way to repeatedly issue the request that is to be audited, it carries out the audit.
While Burp performs its audit checks, it periodically monitors the application's responses to confirm that its session is still valid. If the session is still valid, Burp sets a checkpoint on the audit checks that are complete.
If Burp identifies that the session is no longer valid, it rolls back to the latest checkpoint and resumes from there. This helps to minimize the overhead of session management and avoids indefinite loops if sessions are frequently lost. For example:
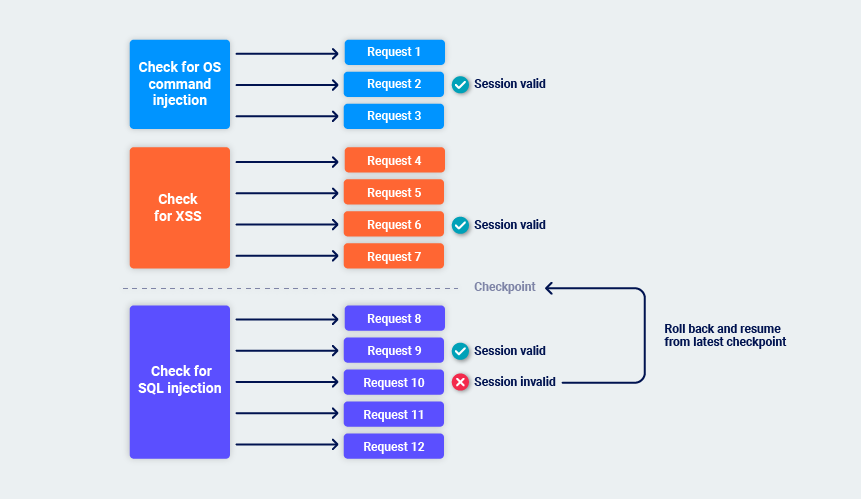
Handling application errors
Performing a full audit of a web application is an invasive process. It is common to encounter problems like connection failures, transmission timeouts, or back-end component outages while a scan is in progress. Additionally, protections such as web application firewalls might drop connections based on factors such as specific payloads or unexpected values in certain parameters.
While auditing, Burp tracks error conditions in a granular way. If a particular action causes an error, Burp marks that action as failed and moves on to the next action. You can configure scans so that if repeated actions fail at the same level of activity, then the whole level is marked as failed. If errors continue to occur, Burp marks progressively more of the scan as failed, as follows:
Individual audit checks.
Individual insertion points.
The entire request that is being audited.
The entire scan.
Burp initially captures details and continues to scan when it encounters an error, as isolated errors are common. Once it completes the audit, Burp performs a number of follow-up passes to retry requests that timed out. This is useful in cases where a particular application component (such as a back-end database) experienced a problem for part of the scan.
Burp can also pause or abort the scan if too many errors are observed, so that you can investigate the problem. You can resume or repeat the scan once the application is stable.